How to reduce Search Console data limits and get 4x the data
Search Console makes it really hard to get all your data out.
The Search Console data limitations are as follows:
- The interface gives you 1,000 rows.
- You'll never see all the small volume keywords, they're removed for anonymity.
- Looker Studio can give you up to 50k rows per day for a site. (But will get really slow.)
- The API when used well can on average 3-4 times that (more for a big site, less for smaller ones).
- BigQuery can give you all the data, but it's not retroactive.
Good news though.
This only gets complicated if you've got a big site, or a lot of possible ranking keywords (perhaps you're an upstart dictionary...)
Let's talk through how we can get the most data out and bypass our limitations.
How do we get the most data from our site?
- Are you small? Looker Studio is by far the best way.
- Do you hit sampling in Looker Studio, or it's agonisingly slow? Time to move to the API.
- API still not giving enough? Time for some clever API usage.
- (bonus) It's never going to hurt to set-up BigQuery.
We'll talk you through how to do it.
Are you a video person?
If so we've got a video version of this post you can watch here.
Small sites - Bypassing the limits in Looker Studio
There's not much to say on this. Build a Looker Studio Search Console report and move on.
Like we said earlier, if you're small this is easy.
Larger sites - API time & Search Console sampling
If that isn't cutting it, then it's time to move onto the API and here our big limit is:
50k rows of data per property, per day, per search type (e.g. web, image etc), sorted by clicks. (i.e. you’ll get the most searched keywords first).
Everything past that is gone.
Also rarely searched keywords (which could identify someone personally) will also not be shown to prevent revealing identities.
Show me some examples of missing data
If you are a large site however the difference can be pretty substantial. Here are some numbers of unique queries we exported for a client in Jan 2024.
We end up 4-5x the amount of data that you get from Looker Studio or using the API in the normal fashion.
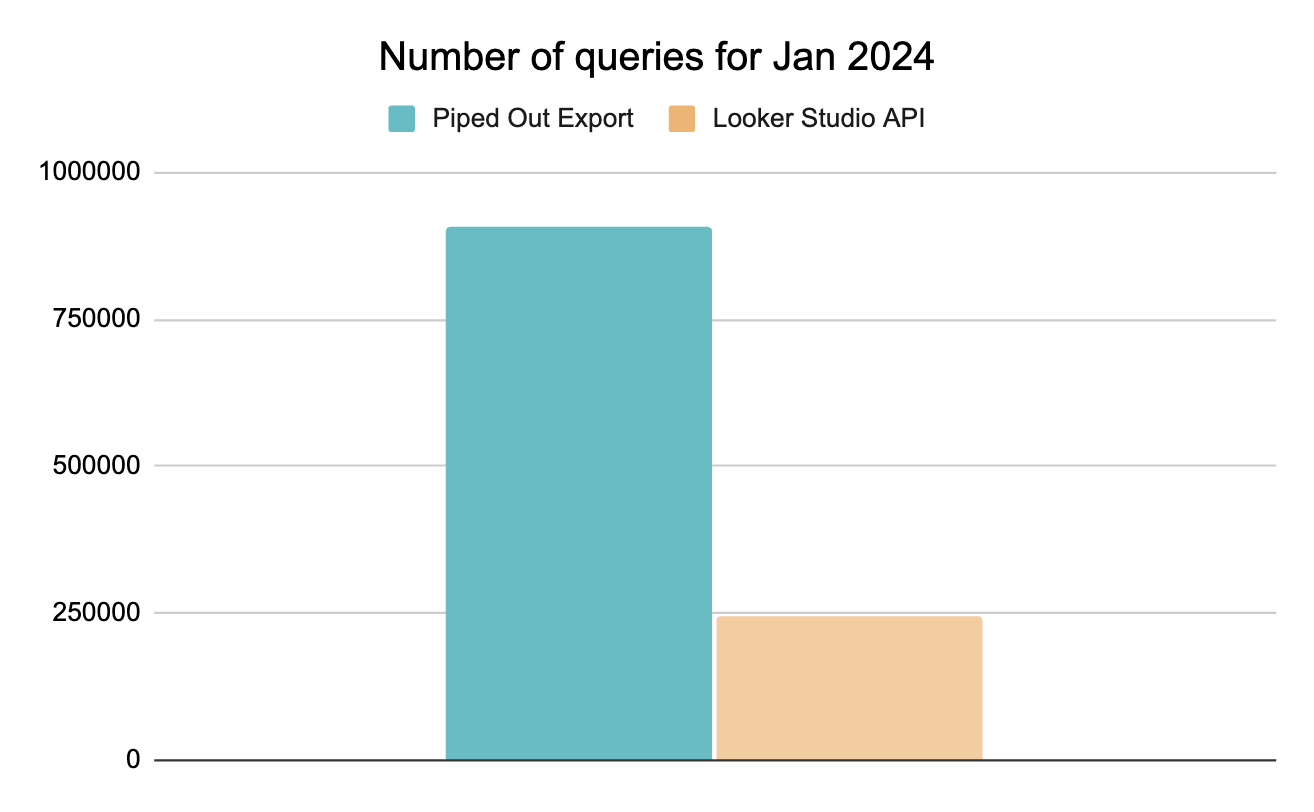
That’s volume of queries, but we also care about filling in as much data as possible.
This graph shows the total clicks registered in Search Console per day. The amount in green is the amount we get queries for.
But we’d also really like to get more information on the orange chunk.
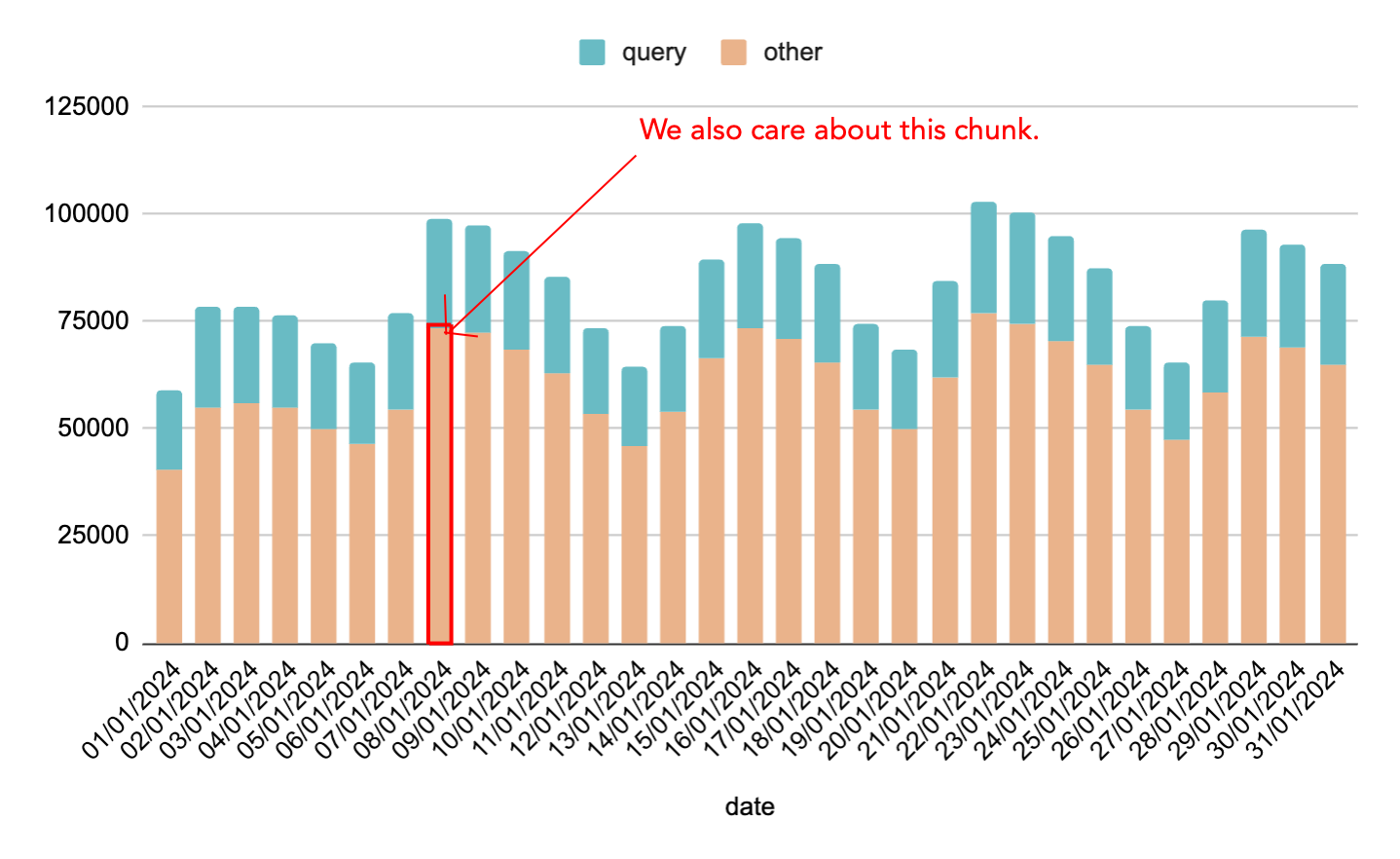
We can’t get queries for this, it’s all part of the long long tail and the bigger your website the bigger this chunk is.
But we can still get more accuracy for the other dimensions. By carefully downloading data we can get a more accurate clicks number for an individual page.
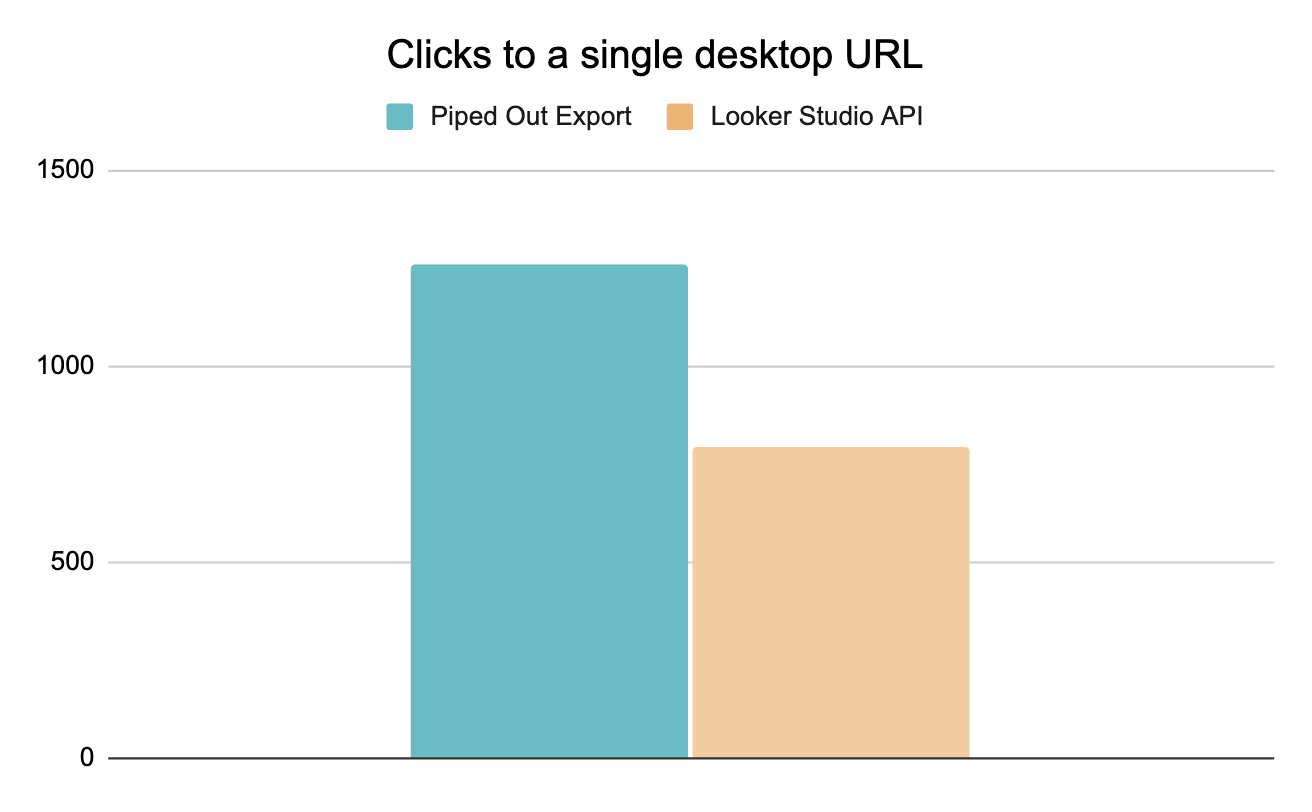
This is really important for two reasons:
More dimensions: We can get country/device/page for it and if you’re looking to join Search Console to GA4 (and even adwords), then this is crucial for accuracy.
We want our numbers to line up with the UI: Nothing ruins people’s trust that looking at a number and realising its 40% below what you can see in the UI. Even though it is actually true.
How to check if you have missing data?
1. Register a subfolder for your main domain in Search Console
Add a subfolder and your main domain to Looker Studio.
2. Make a Looker Studio report and add both of them as sources
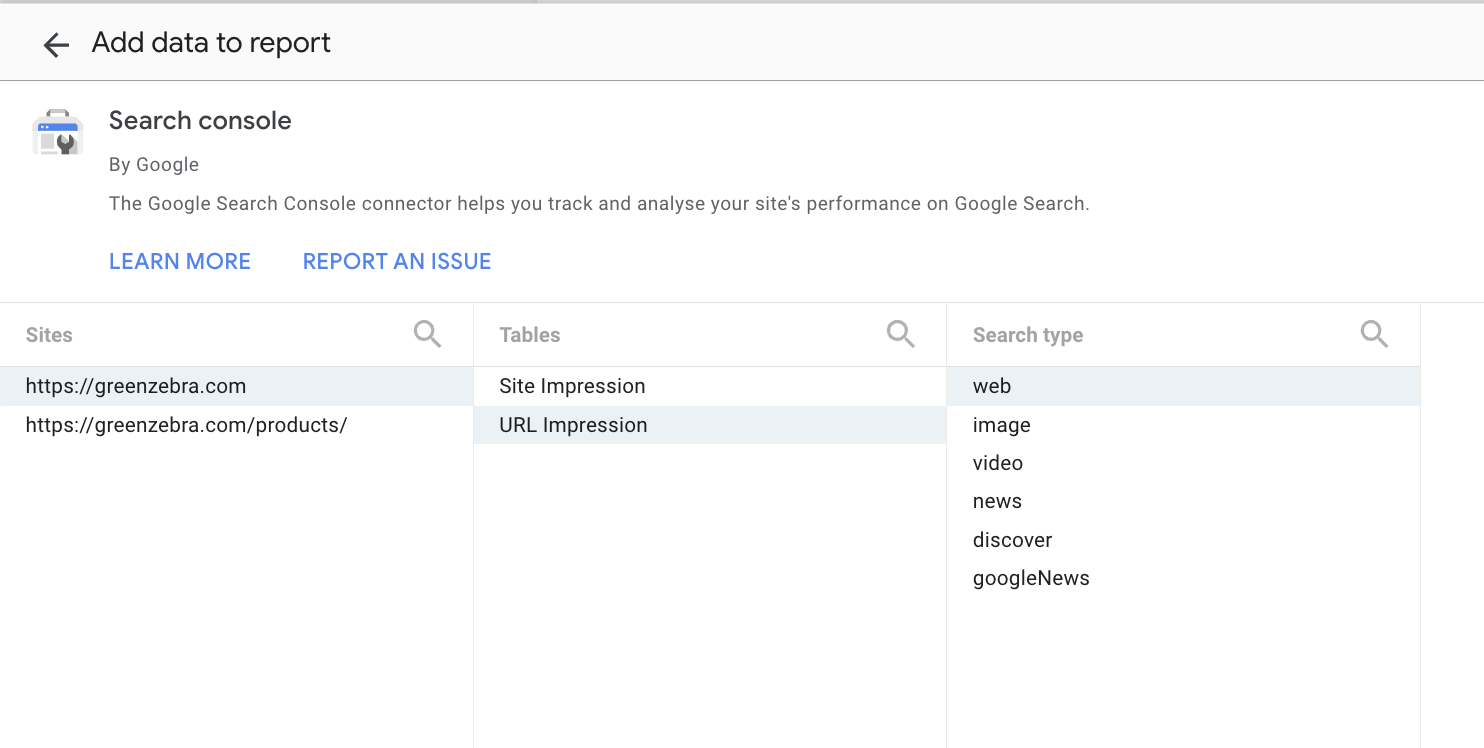
3. Make two tables and distinct count the number of folders in each
For your main site profile, filter it to the same subfolder as the one we’ve registered.
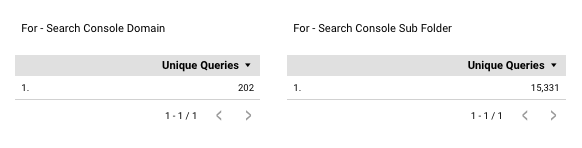
As we can see in this case our main site can see 202 queries in the subfolder, our sub folder can see ~15,000 queries.
How do you get maximum data from Search Console?
What are the big components?
These days there are practically two three pieces:
- Register as many subfolders as you can.
- Download data day by day
- Tie together the different folders
And an optional 4th one (that we’d highly recommend):
- Explicitly fill in cardinality
1. Register all of the subfolders for high traffic sections of your site
Hopefully you’ve already got some of these, but if you don’t you’re going to want to register them.
You’re going to want to register all the subfolders you can for high traffic sections.
For our hypothetical e-commerce site this might look like:
- Domain: greenzebra.com
- https://www.greenzebra.com
- https://www.greenzebra.com/category/
- https://www.greenzebra.com/product/
- https://www.greenzebra.com/product/men/
- https://www.greenzebra.com/product/women/
And so on. You only need to do this for subfolders which actually get traffic you care about. e.g. for most sites you don’t need to worry about registering your internal user account folder e.g.
These only start collecting from whenever you’ve registered them, so the sooner the better.
2. Download the data for each folder day by day.
Time to use the the API to pull the data down day by day.
The limit is day by day, but this usually minimizes API timeouts and retries.
This isn't a full technical walkthrough so at this point we'll point you over to this library for the search console API in python.
If you're not technical then at this point you're probably going to want to pull in your tech team or freelancer.
3. Tie the subfolders together.
The top level properties e.g.
Will contain the subfolders:
So you’ll need to filter out those segments of traffic and stitch in your subfolders.
Also remember those subfolders only count from the day they’ve been registered, so you can’t backdate a new subfolder!
4. Filling in cardinality
But even doing all that, we might still have a gap of missing traffic.
Can we do any better than this?
We can’t get any additional queries. If that’s all you care about then we’ve maxed that out.
But if you do want to:
- Join SC with GA4 to revenue/conv per query.
- (And tie in with Adwords).
- Have your downloaded data match the interface
- So internal teams stumbling into the interface don’t start panicking
We can do a bit more. We can fill in this cardinality.
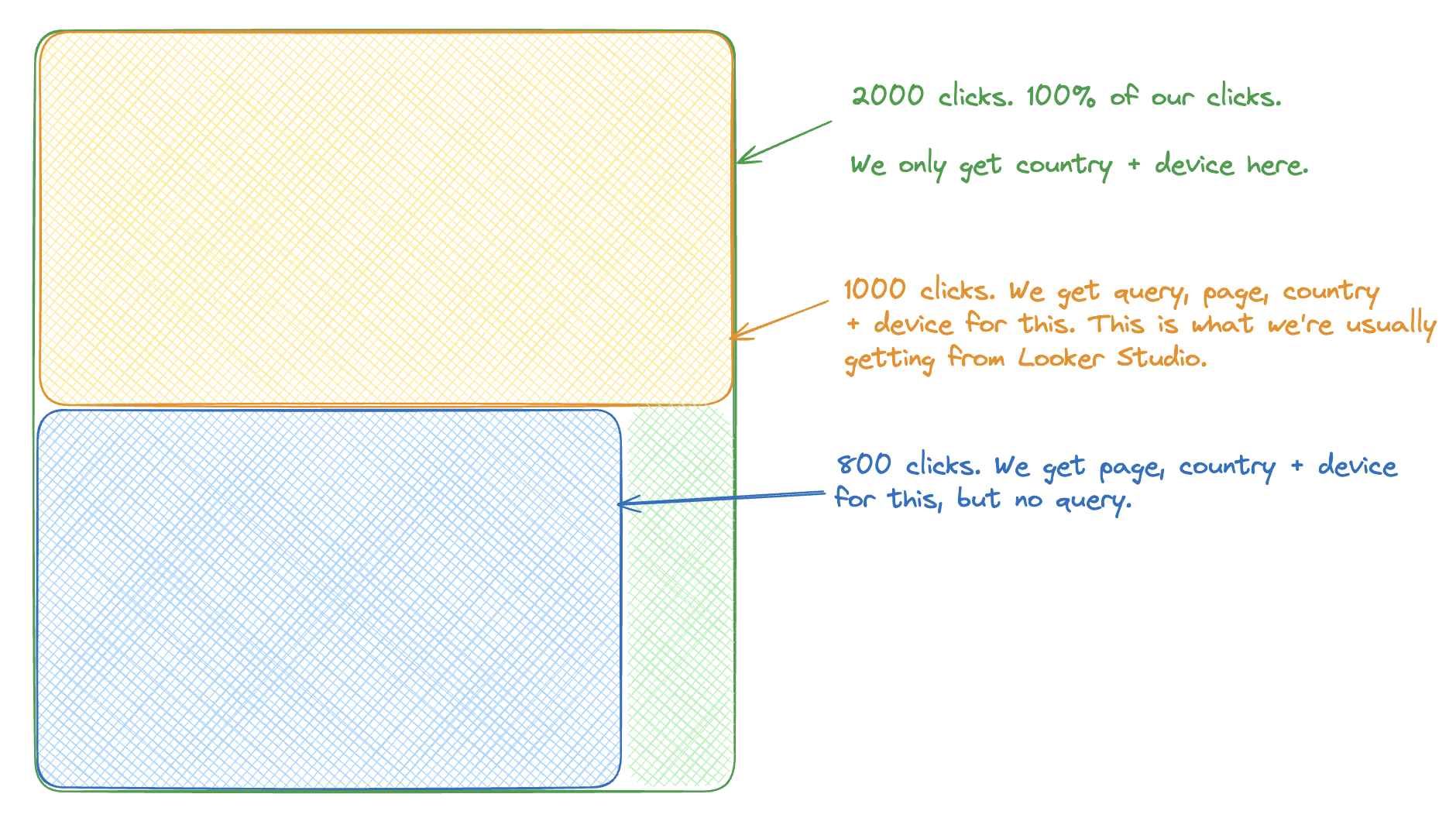
Here’s the top level example:
- The top level number of clicks we have for device, page, country + query is 1000.
- The top level number of clicks we have for country + device is 2000.
We can then see our top level missing data is 1000 clicks.
We go and fetch for different combinations of dimensions. Page and country + device. Where we don’t have a value we just set “(other)”.
We repeat this process for each subfolder, stitch it all together and this gives us numbers that both:
- Add up to the correct totals
- Have as much detail as possible.
5. Bonus set-up and join onto the BigQuery export
We can then join this onto the BigQuery export. This doesn't backfill and we'll have a post on setting up this soon, but it's a great thing to do going forward to keep getting maximum data.
That’s all for today
Hopefully that's given you a top level overview of how to get the largest possible chunk of data from your Search Console.
At the very least register your subfolders and you can always think about the other points in the future.
If you're a bit more ambitious set-up the BigQuery export.
And if you’d like to have us do this for you, please get in touch we can help set you up with a marketing/SEO data warehouse with all the possible Search Console data backfilled as well as joining it with other sources like GA4 and Adwords.